Зарегистрируйтесь сейчас для лучшей персонализированной цитаты!






























One of the things that used to keep me up at night is that troubleshooting a data center network typically involved multiple disparate teams, each having a different view of the network, user interface, and the applications it supports. Historically, it took probing the network manually with complex questions and use the answers derived from custom scripting, spreadsheets, and CLIs for troubleshooting and remediation.
And with scaling into the multi-cloud in modern data center fabrics, the size and scope of deployments are growing into hundreds or even thousands of devices. This results in operational complexity, and the cost of managing these devices has exponentially grown as it takes longer to troubleshoot issues using multiple tools and methods. These multiple tools result in disparate user experiences that result in a lot of time and manual processing spent on troubleshooting and tracking critical network events across global networks. It often requires time to hone into misbehaving devices or collect and analyze data across multiple devices. That can result in downtime which quickly becomes expensive.
Traditional data center network management tools and approaches assume a velocity and volume of change that is well below what is enabled by the cloud and is unable to meet the demands of cloud native applications and digital business.
Cisco Nexus Dashboard is designed to automate, monitor, and analyze your network infrastructure. Innovative architectural approaches were implemented to provide automation and visibility at scale. Nexus Dashboard Insightssimplifies operations for our customers with a modern, stateless microservices architecture that can scale horizontally, leveraging open-source infrastructure code. Insights delivers dynamic correlation, impact analysis, proactive alerts, failure prediction, and remediation, along with operational data visualization. These capabilities help consolidate the number of operational tools needed and reduces application downtime, Mean Time to Identify (MTTI), Mean Time to Resolution (MTTR), and the operating costs.
Here are the key architectural components of the Nexus Dashboard Insights architecture:
Collectors: Nexus Dashboard Insights incorporates universal telemetry collectors. These collectors support multiple input plugins for collecting software and hardware telemetry data streamed from networking infrastructure devices like routers, switches, firewalls, and load balancers.
Data lake: Insights pipeline supports data encoded in JSON or GPB, which gets transformed and stored in a data lake for further processing. Telemetry data from legacy devices that do not support streaming telemetry is retrieved using REST API or SSH and then put into the pipeline for transformation.
Analytics Engine:The analytics engine pipeline uses a serverless compute model. It handles tasks such as data enrichment, anomaly detection, data aggregation, and resource scoring by splitting them into modular tasks with associated task specifications. These tasks are processed independently, and the results are saved in the distributed data lake.
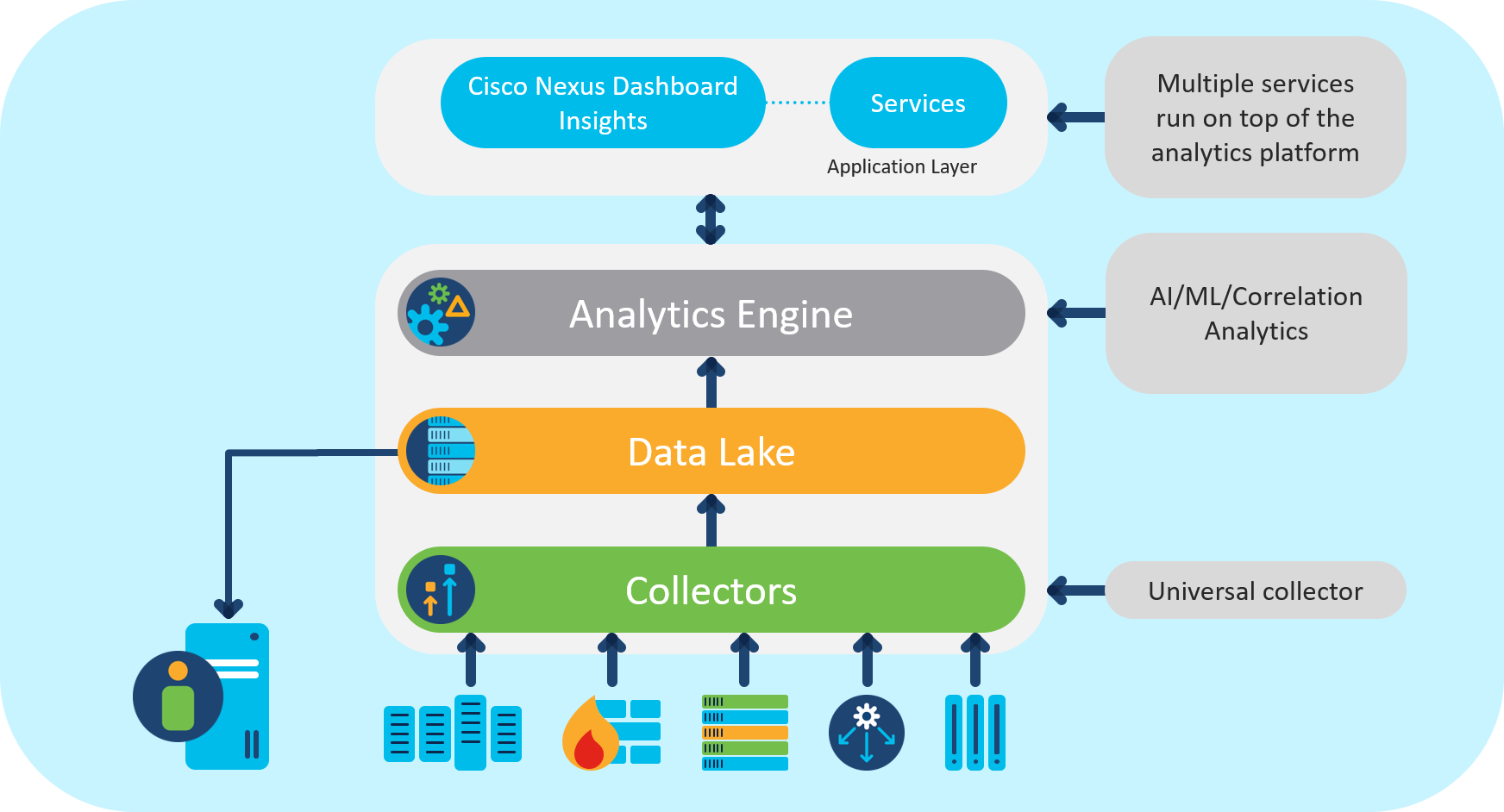 Nexus Dashboard Operations Intelligence Platform
Nexus Dashboard Operations Intelligence Platform Today, we are leveraging best-in-class AI/ML technologies to automate a number of these tasks which were being done manually on CLIs or using custom python scripts. This has led to powerful forecasting and anomaly detection use cases to generate an alert based on analytics of the time-series network data, paving the path towards proactive and predictive capabilities.
Insights proactively streams software and hardware telemetry from across the fabric. It uses AI/ML technology to create a network-specific baseline for different Key Performance Indicators (KPIs). These baselines are continuously updated to reflect dynamic network behavior. An anomaly alert is generated when the network state crosses the thresholds band set around the baseline. These anomalies can further trigger user-specified actions such as generating email notifications or auto-remediation.
Insights has been built on the principle that beyond identifying a problem in the network, there is a strong need to make the complex monitoring of IT operations simple. We embarked on an automation journey starting with taking additional steps to identify the impact caused by the issue/s and the resulting remediation steps.
We address the architectural demands placed on the modern networks by:
This allows us to automate and manage legacy data-intensive processes while simultaneously embracing new cloud-driven data frameworks.
 Cisco Nexus Dashboard Alerts Summary
Cisco Nexus Dashboard Alerts Summary Stay tuned to the next set of blogs that will delve into upcoming Nexus Dashboard capabilities and use cases based on this new "built from the ground up" architectural approach.
Cisco Nexus Dashboard
Cisco Nexus Dashboard Insights
Cisco Nexus Dashboard User Guide
Cisco Nexus Dashboard Insights Whitepaper
 Горячие метки:
Главная страница
Центр обработки данных
Cisco Full-Stack Observability (FSO)
AI/ML
AIOps
big data analytics
Analytics and Automation
analytics and assurance
Горячие метки:
Главная страница
Центр обработки данных
Cisco Full-Stack Observability (FSO)
AI/ML
AIOps
big data analytics
Analytics and Automation
analytics and assurance
Зарегистрируйтесь по электронной почте сейчас для еженедельной акции акции
100% free, Unsubscribe any time!
Add 1: Room 605 6/F FA YUEN Commercial Building, 75-77 FA YUEN Street, Mongkok KL, HongKong Add 2: Room 405, Building E, MeiDu Building, Gong Shu District, Hangzhou City, Zhejiang Province, China
Whatsapp/ тел: +8618057156223 * телефон: *: 0086 571 86729517 Tel in HK: 00852 66181601
Электронная почта: [email protected]
 English
English Pусский
Pусский Français
Français Español
Español Português
Português

