Зарегистрируйтесь сейчас для лучшей персонализированной цитаты!


















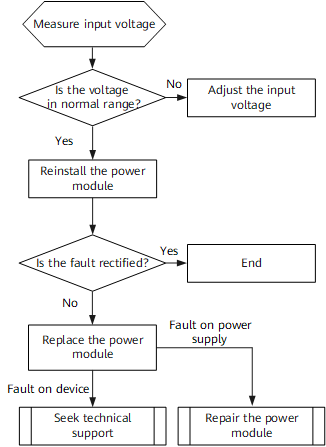












Numerous observers have predicted that 2024 will be the year enterprises turn generative AI such as OpenAI's GPT-4 into actual corporate applications. Most likely, such applications will begin with the simplest kinds of infrastructure, stringing together a large language model such as GPT-4 with some basic data management.
Enterprise apps will start with simple tasks such as searching through text or images to find the match to a natural-language search.
Also: Pinecone's CEO is on a quest to give AI something like knowledge
A perfect candidate to make that happen is a Python library called SuperDuperDB, created by the venture capital-backed company of the same name, founded this year.
SuperDuperDB is not a database but an interface that sits between a database such as MongoDB or Snowflake and a large language model or other GenAI program.
That interface layer makes it simple to perform several very basic operations on corporate data. Using natural language queries in a chat prompt, one can query an existing corporate data set -- such as documents -- more extensively than is possible with a typical keyword search. One can upload images of, say, products to an image database and then query that database by showing an image and looking for a match.
Likewise, moments in videos can be retrieved from an archive of videos, by typing themes or features. Records of voice messages can be searched as a text transcript, making a basic voicemail assistant.
The technology also has uses for data scientists and machine learning engineers who want to refine AI programs using proprietary corporate data.
Also: Microsoft's GitHub Copilot pursues the absolute 'time to value' of AI in programming
For example, to "fine-tune" an AI program such as an image recognition model, one has to hook up an existing database of images to the machine learning program. The challenge is how to get the image data into and out of the machine learning program, and how to define variables of the training process, such as the loss to be minimized. SuperDuperDB offers simple function calls to simplify all those things.
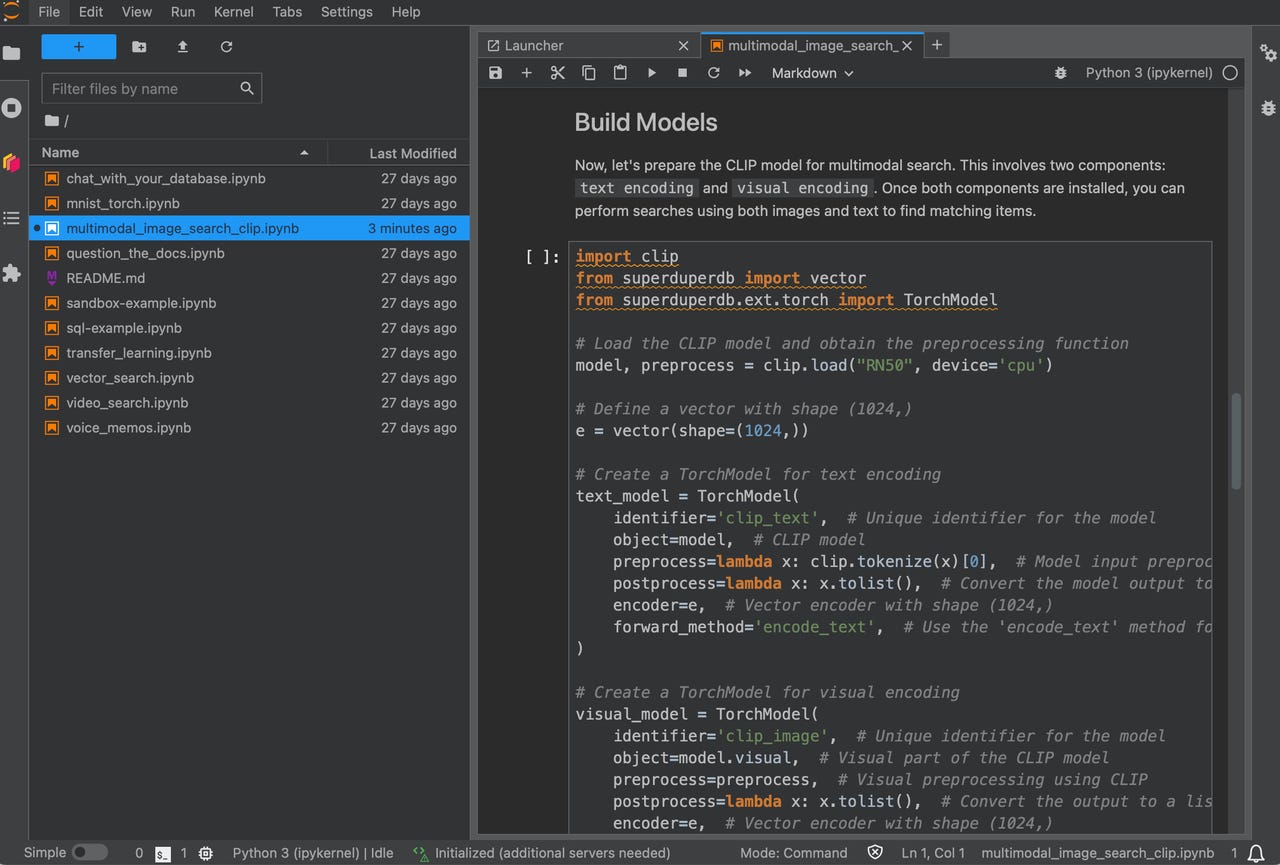
A key aspect of many of those functions is to convert different data types -- text, image, video, audio -- into vectors, strings of numbers that can be compared against one another. Doing so allows SuperDuperDB to perform "similarity search," where the vector of a text phrase, for example, is compared to a database full of voicemail transcripts to retrieve the message most closely matching the query.
Mind you, SuperDuperDB is not a vector database like Pinecone, a commercial program. It's a simpler form of organizing vectors called a "vector index."
Also: Pinecone's CEO is on a quest to give AI something like knowledge
The SuperDuperDB program, which is open-source, is installed like a typical Python installation from the command line or loaded as a pre-built Docker container.
The first step to working with SuperDuperDB can either be setting up a data store from scratch, or working with an external data store. In either case, you'll want to have a data repository such as MongoDB or a SQL-based database.
SuperDuperDB handles all data, including newly created data and data fetched from the database, via what it calls an "encoder," which lets the programmer define data types. These encoded types -- text, audio, image, video, etc. -- can be stored in MongoDB as "documents" or in SQL-based databases as a table schema. It's also possible to store very large data items, such as video files, in local storage when they exceed the capacity of either MongoDB or the SQL database.
Also: Bill Gates predicts a 'massive technology boom' from AI coming soon
Once a data set is chosen or created, neural net models can be imported from libraries such as SciKit-Learn or one can use a very basic built-in inventory of neural nets such as the Transformer, the original large language model. One can also call APIs from commercial services such as OpenAI and Anthropic. The core function of having the model make predictions is done with a simple call to a ".predict" function built into SuperDuperDB.
When working with a large language model or an image model like Stable Diffusion or Dall-E, the neural net will seek to retrieve answers from the database by performing the vector similarity search. That's as simple as calling a ".like" function and passing it the query string.
It's possible to make more complex apps by assembling multiple stages of functionality with SuperDuperDB, such as using similarity search to retrieve items from a database and then passing those items to a classifier neural net.
The company has added functions that make an app more of a production system. They include a service called Listeners that re-run predictions whenever the underlying database is updated. Various functions in SuperDuperDB can also be run as separate daemons to improve performance.
Also: How LangChain turns GenAI into a genuinely useful assistant
This year will witness a great deal of evolution in programs such as SuperDuperDB, making them more robust still for production purposes. You can expect SuperDuperDB to evolve alongside other important emerging infrastructures such as the LangChain framework and commercial tools such as the Pinecone vector database.
While there's a lot of ambitious talk about enterprise use of GenAI, it probably starts right here, with the kinds of humble tools that can be picked up by the individual programmer.
If you'd like to get a quick feel for SuperDuperDB, head over to the demo on the company's Web site.
 Горячие метки:
3. Инновации
Горячие метки:
3. Инновации
Зарегистрируйтесь по электронной почте сейчас для еженедельной акции акции
100% free, Unsubscribe any time!
Add 1: Room 605 6/F FA YUEN Commercial Building, 75-77 FA YUEN Street, Mongkok KL, HongKong Add 2: Room 405, Building E, MeiDu Building, Gong Shu District, Hangzhou City, Zhejiang Province, China
Whatsapp/ тел: +8618057156223 * телефон: *: 0086 571 86729517 Tel in HK: 00852 66181601
Электронная почта: [email protected]
 English
English Pусский
Pусский Français
Français Español
Español Português
Português

