Зарегистрируйтесь сейчас для лучшей персонализированной цитаты!






























In my prior blog entry, I described the basics of Open MPI's tree-based launching system over ssh (yes, there are still some valid / good reasons for using ssh over a native job scheduler / resource manager's parallel launch mechanisms...).
That entry got a little long, so I split the rest of the discussion into a separate blog entry.
The prior entry ended after describing that Open MPI uses a binomial tree-based launcher.
One thing I didn't say in the last entry: the tree-based launcher is not only an optimization, it's alsonecessaryfor launching larger parallel jobs. There are operating system-imposed limits on the number of open file descriptors in a process, meaning that mpirun simplycan'topen an ssh session to all remote servers as the number of servers scales up.
There were real-world cases of users hitting those limits, therebyforcingthe move to a more scalable, tree-based system.
Since the initial implementation of the tree-based launcher in 2009, server CPUs and networks have gotten significantly faster: an individual ssh session is significantly faster to establish than it was six years ago. As a direct result, Open MPI added two more improvements to its ssh tree-based launch.
The first was to remove the serialization of ssh sessions on a single server:
Instead, overlap initiating all the ssh connections from each interior node in the tree. Meaning: fork all the ssh connections at once, and then process them as their connections start progressing. Or, more simply: parallelize the initiation of ssh connections.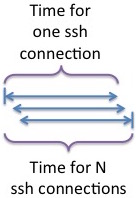
Not only does the overlap of ssh session initiation significantly speedup the overall process:
The second Open MPI improvement was to switch from a binomial tree to a radix tree.
Specifically, by default:
While users can certainly override the default radix value at run time, these defaults reflect two observations:
These two improvements - pipelining ssh and using a radix tree - together make launching via ssh quite viable, even at large scale.
More improvements are certainly possible (and desirable). For example, there is ongoing work to separate the "out of band" message routing from the job launch topology, thereby allowing smaller radixes, more parallelization, and potentially shorter overall job launch time.
Stay tuned for future blog entries on this topic!
 Горячие метки:
HPC (HPC)
mpi
Open MPI
Горячие метки:
HPC (HPC)
mpi
Open MPI
Зарегистрируйтесь по электронной почте сейчас для еженедельной акции акции
100% free, Unsubscribe any time!
Add 1: Room 605 6/F FA YUEN Commercial Building, 75-77 FA YUEN Street, Mongkok KL, HongKong Add 2: Room 405, Building E, MeiDu Building, Gong Shu District, Hangzhou City, Zhejiang Province, China
Whatsapp/ тел: +8618057156223 * телефон: *: 0086 571 86729517 Tel in HK: 00852 66181601
Электронная почта: [email protected]
 English
English Pусский
Pусский Français
Français Español
Español Português
Português

