Зарегистрируйтесь сейчас для лучшей персонализированной цитаты!






























Today's blog post is written by Joshua Ladd, Open MPI developer and HPC Algorithms Engineer at Mellanox Technologies.
At some point in the process of pondering this blog post I noticed that my subconscious had, much to my annoyance, registered a snippet of the chorus to Paul Simon's timeless classic "50 Ways to Leave Your Lover" with my brain's internal progress thread. Seemingly, endlessly repeating, billions of times over (well, at least ten times over) the catchy hook that offers one, of presumably 50, possible ways to leave one's lover -"Hop on the bus, Gus." Assuming Gus does indeed wish to extricate himself from a passionate predicament, this seems a reasonable suggestion. But, supposing Gus has a really jilted lover; his response to Mr. Simon's exhortation might be "Just how many hops to that damn bus, Paul?"
HPC practitioners may find themselves asking a similar question, though in a somewhat less contentious context (pun intended.) Given the complexity of modern HPC systems with their increasingly stratified memory subsystems and myriad ways of interconnecting memory, networking, computing, and storage components such as NUMA nodes, computational accelerators, host channel adapters, NICs, VICs, JBODs, Target Channel Adapters, etc., reasoning about process placement has become a much more complex task with much larger performance implications between the "best" and the "worst" placement policies. To compound this complexity, the "best" and "worse" placement necessarily depends upon the specific application instance and its communication and I/O pattern. Indeed, an in-depth discussion on Open MPI's sophisticated process affinity system is far beyond the scope of this humble blog post and I refer the interested reader to the deep dive talk Jeff gave at Euro MPI on this topic.
In this posting, I'll only consider the problem framed by Gus' hypothetical query; How can one map MPI processes as close to an I/O device as possible thereby minimizing data movement or 'hops' through the intranode interconnect for those processes? This is a very reasonable request but the ability to automate this process has remained mostly absent in modern HPC middleware. Fortunately, powerful tools such as "hwloc" are available to help us with just such a task. Hwloc usually manipulates processing units and memory, but it can also discover I/O devices and report their locality as well. In simplest terms, this can be leveraged to place I/O intensive applications on cores near the I/O devices they use. Whereas Gus probably didn't have the luxury to choose his locality so as to minimize the number of hops necessary to get on his bus, Open MPI, with the help of hwloc, now provides a mechanism for mapping MPI processes to NUMA nodes "closest" to an I/O device.
 Figure 1: hwloc depiction of an iMac.
Figure 1: hwloc depiction of an iMac.OMPI 1.7.2 and later support mapping by node, board, socket, core, and thread. In OMPI 1.7.3 we introduced the option to map by distance to a peripheral I/O device with the--map-by distoption. The "mindist mapper", as it's referred to, essentially organizes PCI locality information culled from hwloc and imposes an ordering based on parent-child object relationships. The mindist mapper is an extension of Open MPI's Level 2 command line interface (CLI) for process mapping.
In Figure 1, we see the graphical output of running "lstopo" on my personal iMac. OS X unfortunately does not provide any functionality for hwloc to query my PCIe bus. The following command therefore results in a failure, since a human explicitly asked for something that couldn't be done:
shell$mpirun -np 4 --map-by dist:sda ./ring_c--------------------------------------------------------------------------No PCI locality information could be found on at least one node:Node: Joshuas-iMacOpen MPI therefore cannot map the application as specified.--------------------------------------------------------------------------
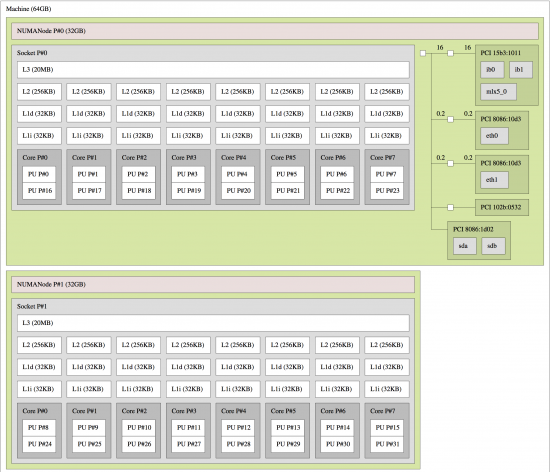 Figure 2: hwloc depiction of Sputnik.
Figure 2: hwloc depiction of Sputnik.Figure 2 shows the system topology of a single server of Mellanox's R&D system, "Sputnik", which consists of two Sandy-Bridge NUMA servers. Each NUMA node has eight physical cores with two hyperthreads per core. We are able to clearly see that this system has a single Mellanox Connect-IB HCA, mlx5_0, attached to socket P#0. Launching an MPI application with the following command:
shell$mpirun -np 16 --map-by dist:mlx4_0 --bind-to core ...
results in processes 0 -7 being mapped to socket P#0 of the first node, and processes 7 -15 being mapped to socket P#1. As directed, MPI processes 0 -7 are bound to cores P#[0-7] and processes 8 -15 are bound to cores P#[8-15]. If no "-bind-to" option is specified with the mindist mapper, the default binding is -bind-to core. It's often helpful to use the "-report-bindings" and "-display-map" options to get a visual confirmation that your processes are indeed mapped and bound as you had intended them. Doing so for the above example results in the following being displayed to stdout (snipped and reformatted a little for inclusion here in the blog):
======================== JOB MAP ========================Data for node: sputnik1 Num slots: 32 Max slots: 0 Num procs: 16Process OMPI jobid: [63009,1] App: 0 Process rank: 0Process OMPI jobid: [63009,1] App: 0 Process rank: 1...Process OMPI jobid: [63009,1] App: 0 Process rank: 15Data for node: sputnik2 Num slots: 32 Max slots: 0=============================================================[sputnik1.vbench.com:10290] MCW rank 0 bound to socket 0[core 0[hwt 0-1]]: \ [BB/../../../../../../..][../../../../../../../..][sputnik1.vbench.com:10290] MCW rank 1 bound to socket 0[core 1[hwt 0-1]]: \ [../BB/../../../../../..][../../../../../../../..]...[sputnik1.vbench.com:10290] MCW rank 15 bound to socket 1[core 15[hwt 0-1]]: \ [../../../../../../../..][../../../../../../../BB]
There are two modes for mapping by dist: span and not-span. The span mode essentially operates as if there was just a single "super-node" in the system -i.e., it balances the load across all objects of the indicated type regardless of their location. In contrast, the non-span mode operates similar to byslot mapping. All slots on each server are filled, assigning each process to an object on that node in a balanced fashion, and then the mapper moves on to the next node. Thus, processes tend to be "front loaded" onto the list of servers, as opposed to being "load balanced" in the span mode. The default mode is not-span and one must pass an additional "span" modifier to use the span mode like so: -map-by dist:mlx4_0,span
Launching an MPI application with the following command across two Sputnik servers
shell$mpirun -np 16 --map-by dist:mlx4_0,span --bind-to core \ --display-map --report-bindings ...
results in processes 0 -7 being bound to cores P#[0-7] on socket P#0 of the first Sputnik server and processes 8 -15 being bound to cores P#[0-7] on socket P#0 of the second Sputnik server. This is confirmed by examining the mapping and binding pretty-print (snipped/reformatted):
======================== JOB MAP ========================Data for node: sputnik1 Num slots: 32 Max slots: 0 Num procs: 8Process OMPI jobid: [64047,1] App: 0 Process rank: 0Process OMPI jobid: [64047,1] App: 0 Process rank: 1...Process OMPI jobid: [64047,1] App: 0 Process rank: 7Data for node: sputnik2 Num slots: 32 Max slots: 0 Num procs: 8Process OMPI jobid: [64047,1] App: 0 Process rank: 8Process OMPI jobid: [64047,1] App: 0 Process rank: 9...Process OMPI jobid: [64047,1] App: 0 Process rank: 15=============================================================[sputnik1.vbench.com:09280] MCW rank 0 bound to socket 0[core 0[hwt 0-1]]: \ [BB/../../../../../../..][../../../../../../../..][sputnik1.vbench.com:09280] MCW rank 1 bound to socket 0[core 1[hwt 0-1]]: \ [../BB/../../../../../..][../../../../../../../..]...[sputnik1.vbench.com:09280] MCW rank 7 bound to socket 0[core 7[hwt 0-1]]: \ [../../../../../../../BB][../../../../../../../..][sputnik2.vbench.com:08815] MCW rank 8 bound to socket 0[core 0[hwt 0-1]]: \ [BB/../../../../../../..][../../../../../../../..][sputnik2.vbench.com:08815] MCW rank 9 bound to socket 0[core 1[hwt 0-1]]: \ [../BB/../../../../../..][../../../../../../../..]...[sputnik2.vbench.com:08815] MCW rank 15 bound to socket 0[core 7[hwt 0-1]]: \ [../../../../../../../BB][../../../../../../../..]
Sputnik is a hyperthreaded machine, let's examine the following the command line
shell$mpirun -np 16 --map-by dist:mlx4_0,span --bind-to hwthread \ --display-map --report-bindings ...
This results in the same mapping as in the above example, however MPI processes are now bound to a single hyperthread (instead of floating between the two on each core - prettyprint snipped/reformatted):
======================== JOB MAP ========================Data for node: sputnik1 Num slots: 32 Max slots: 0 Num procs: 8Process OMPI jobid: [62744,1] App: 0 Process rank: 0Process OMPI jobid: [62744,1] App: 0 Process rank: 1...Process OMPI jobid: [62744,1] App: 0 Process rank: 7Data for node: sputnik2 Num slots: 32 Max slots: 0 Num procs: 8Process OMPI jobid: [62744,1] App: 0 Process rank: 8Process OMPI jobid: [62744,1] App: 0 Process rank: 9...Process OMPI jobid: [62744,1] App: 0 Process rank: 15=============================================================[sputnik1.vbench.com:09970] MCW rank 0 bound to socket 0[core 0[hwt 0]]: \ [B./../../../../../../..][../../../../../../../..][sputnik1.vbench.com:09970] MCW rank 1 bound to socket 0[core 1[hwt 0]]: \ [../B./../../../../../..][../../../../../../../..]...[sputnik1.vbench.com:09970] MCW rank 7 bound to socket 0[core 7[hwt 0]]: \ [../../../../../../../B.][../../../../../../../..][sputnik2.vbench.com:09241] MCW rank 8 bound to socket 0[core 0[hwt 0]]: \ [B./../../../../../../..][../../../../../../../..][sputnik2.vbench.com:09241] MCW rank 9 bound to socket 0[core 1[hwt 0]]: \ [../B./../../../../../..][../../../../../../../..]...[sputnik2.vbench.com:09241] MCW rank 15 bound to socket 0[core 7[hwt 0]]: \ [../../../../../../../B.][../../../../../../../..]
Additionally, on systems endowed with Open Fabrics devices (e.g. Mellanox HCAs), you may specify "auto" in lieu of an explicit device name and the mindist mapper will attempt to find and map processes nearest an OFA device for you automagically: --map-by dist:auto.
 Figure 3: hwloc depiction of Apollo.
Figure 3: hwloc depiction of Apollo.If no device, or more than one OFA device is found, an error message will prompt the user to choose a specific HCA. Figure 3 shows the system topology of our "Apollo" system which has two Mellanox HCAs attached to the first socket, namely, a Connect-IB card, mlx5_0, and a ConnectX-3 card, mlx4_0. On Apollo, the following commands are legal: -map-by dist:mlx4_0 or -map-by dist:mlx5_0, but -map-by dist:auto is ambiguous because more than one OFA device will be discovered. a In this case, a warning will be printed, and the job will continue by falling back onto a "byslot" mapping. Similarly, if a device is specified and it cannot be found, the same behavior will occur (print a warning, fallback to "byslot"). For example, if I were to launch an application on Sputnik with the following command:
shell$mpirun -np 16 --map-by dist:mlx4_0 --bind-to core \ --display-map --report-bindings ...
I would see the following warning because Sputnik does not have an mlx4_0 device, however, the job still runs with the "byslot" mapping policy:
--------------------------------------------------------------------------No PCI locality information could be found on at least one node. Please, upgrade BIOS to expose NUMA info.Node: sputnik1Open MPI will map the application by default (BYSLOT).--------------------------------------------------------------------------
As a simple, yet powerful application of the mindist mapper, we consider a hierarchical collective algorithm. Without getting into details, most implementations of such algorithms have a "fan-in" phase where data converges on a node leader. Subsequent to the fan-in, the leader exchanges data with all other node leader. In Mellanox's collective implementations, we usually just select the smallest MPI rank on each node to serve as the leader. Coupling this with the mindist mapper ensures that node leaders will always be nearest the HCA whenever--map-by distis passed.
In conclusion, the mindist mapper is a simple and effective way to map MPI processes near a desired I/O device. These examples have been tailored to HCAs, but they could just as easily have been Ethernet interfaces or storage devices. How effective this mapping is in terms of performance depends entirely on the application and its communication and/or I/O pattern. Ultimately, the onus still falls on the developer to make informed decisions about process placement. However, the mindist mapper provides one more tool for the HPC practitioner's toolbox to help reason with all of this complexity. So, make a new plan, Stan: Download the latest Open MPI 1.7.3 or beyond and try the mindist mapper today!
 Горячие метки:
HPC (HPC)
NUNA
process affinity
NUMA
Горячие метки:
HPC (HPC)
NUNA
process affinity
NUMA
Зарегистрируйтесь по электронной почте сейчас для еженедельной акции акции
100% free, Unsubscribe any time!
Add 1: Room 605 6/F FA YUEN Commercial Building, 75-77 FA YUEN Street, Mongkok KL, HongKong Add 2: Room 405, Building E, MeiDu Building, Gong Shu District, Hangzhou City, Zhejiang Province, China
Whatsapp/ тел: +8618057156223 * телефон: *: 0086 571 86729517 Tel in HK: 00852 66181601
Электронная почта: [email protected]
 English
English Pусский
Pусский Français
Français Español
Español Português
Português

